

## String 클래스
어떤 프로그램이건 문자열은 데이터로서 아주 많이 사용된다.
그렇기 때문에 문자열을 생성하는 방법과 추출, 비교, 찾기, 분리, 변환등을 제공하는 메소드를 잘 익혀두어야 한다.
# String 생성자
자바의 문자열은 java.lang 패키지의 String 클래스의 인스턴스로 관리된다.
소스상에서 문자열 리터럴은 String 객체로 자동 생성되지만,
String 클래스의 다양한 생성자를 이용해서 직접 String 객체를 생성할수도 있다.
String 클래스는 Deprecated(비권장) 된 생성지를 제외하고 약 13개의 생성자를 제공한다
Deprecated는 예전 자바 버전에서는 사용되었으나, 현재 버전과 차후 버전에서는 사용하지 말라는 뜻이다.
어떤 생성자를 이용해서 String 객체를 생성할지는 제공되는 매개값의 타입에 달려 있다.
다음은 사용 빈도수가 높은 생성자들이다.
파일의 내용을 읽거나, 네트워크를 통해 받은 데이터는 보통 byte[ ] 배열이므로 이것을 문자열로 변환하기 위해 사용된다.
-네트워크를 통해서 데이터를 직접 받거나 파일을 읽을때에는 byte를 사용해야 한다.
-파일을 읽거나 데이터를 주고 받을때 주로 byte 배열로 변환이 되어야 한다.
-String str = "홍길동"; = 기존에 쓰는 String 쓰는 방식
-String str1 = new String("홍길동"); = 너무 자주 사용하다보니 원래는 이 방식인데, 위처럼 함축 시켜놓았다.
-UTF-8 3Byte / EUC-KR 2Byte (기존에 UTF로 만들었던 파일을 EUC-KR로 변경하려면 글자가 깨진다)
-아래에 String charsetName에 인코딩 방식을 따로 넣어줄 수 있다.
-서로 프로젝트 중에 한 명이라도 다른 인코딩 방식을 사용하면 모든 프로젝트가 한 번에 글자가 깨지게 된다.
-영어를 저장하게 되면 운영체제는 해당 문자를 ASCII코드를 사용하여 데이터를 저장한다.
-영어가 아닌 다른 문자들을 표현하려면 인코딩 방식을 지정해야 한다.( UTF-8, EUC-KR, MS949)
-영어 이외의 값은 유니코드 표기법으로 표현이 된다.
-이클립스의 기본 인코딩 방식은 UTF-8 방식을 사용한다.
-UTF-8 : 한글을 표기시 3Byte를 사용한다.
-EUC-KR : 한글을 표기시 2Byte를 사용한다.
-new String(byte[] bytes, int offset, int length);
-> ing offset 인덱스 몇 부터~ int length개 만큼 String 객체를 생성할 것 이다. index[5]~3 (5, 6, 7)

// 아래 String은 다 각각의 오버로딩이 되어있는 String의 생성자들이다.
byte [] byteValue = {104, 101, 108, 108, 111}; // byte 배열
// Stirng()
String str1 = new String();
System.out.println("1) 기본생성자 : " + str1);
// String("문자열")
String str2 = new String("자동차운전");
System.out.println("2) " + str2);
// String(byte[] byte); 아스키 코드를 넣어서 hello가 값으로 나온다.
String str3 = new String(byteValue);
System.out.println("3) " + str3);
// String(byte[] byte; charset charset);
String str4 = new String(byteValue, Charset.forName("ASCII"));
System.out.println("4) " + str4);
// String(byte[] byte, int offset, int length);
String str5 = new String(byteValue, 1, 3, Charset.forName("ASCII"));
System.out.println("5) " + str5);
// String(byte[] byte, int offset, int length, charSet charset);
String str6 = new String(byteValue, 1, 4);
System.out.println("6) " + str6);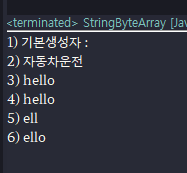
String str = "문자열스트링";
System.out.println(str);
byte [] bytes = str.getBytes();
int result = bytes.length;
System.out.println("바이트의 배열의 길이 : " + result);
System.out.print("[");
for(int i = 0; i < bytes.length; i++) {
byte b = bytes[i];
System.out.print(b);
if(i < bytes.length -1) {
System.out.print(", ");
}
}
System.out.print("]");
System.out.println();
// Arrays가 가지고 있는 toString 값을 출력한다.
System.out.println(Arrays.toString(bytes));
-문자를 byte 배열로 받은 뒤에, 인코딩 방식을 바꿔서 출력해보기.
// str
String str = "자동차운전자"; // 임의의 문자열 생성
byte [] bytes1 = str.getBytes(); // 문자열을 바이트 배열로 변환하여 대입
System.out.println("바이트 배열의 길이 : " + bytes1.length + "byte");
// str1
String str1 = new String(bytes1); // byte배열을 매개변수로 String 문자열 생성
System.out.println("str1 : " + str1);
System.out.println();
// str2
try {
byte [] bytes2 = str.getBytes("UTF-8");
String str2 = new String(bytes2,"UTF-8");
System.out.println("바이트 배열의 길이 : " + bytes2.length + "byte");
System.out.println("str2 : " + str2);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
System.out.println();
// str3
try {
byte [] bytes3 = str.getBytes("EUC-KR");
System.out.println("바이트 배열의 길이 : " + bytes3.length + "byte");
String str3 = new String(bytes3, "EUC-KR");
System.out.println("str3 : " + str3);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
System.out.println();
// str4
try {
byte [] bytes4 = str.getBytes("UTF-8");
System.out.println("바이트 배열의 길이 : " + bytes4.length + "byte");
String str4 = new String(bytes4, "EUC-KR");
System.out.println("str4 :" + str4);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
System.out.println();
// str5
byte[] bytes5;
try {
bytes5 = str.getBytes("EUC-KR");
System.out.println("바이트 배열의 길이 : " + bytes5.length + "byte");
String str5 = new String(bytes5, "UTF-8");
System.out.println("str5 : " + str5);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
# String 메소드
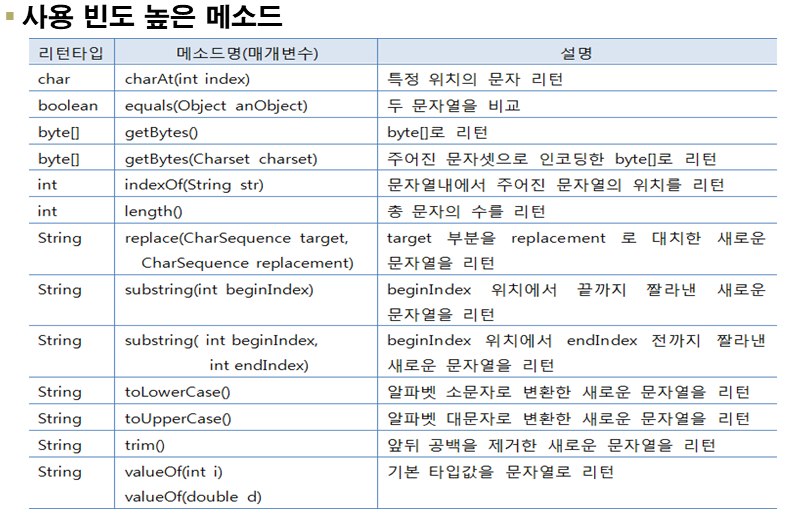
String은 문자열의 추출, 비교, 찾기, 분리, 변환 등과 같은 다양한 메소드를 가지고 있다.
String 클래스의 메소드는 모든 프로그램에 자주 사용되기 때문에
코딩을 많이 해본 사람은 메소드의 이름을 거의 다 기억하고 있다.
메소드 이름이 곧 메소드의 기능을 뜻하기 때문에 조금만 코딩해 보면 쉽게 기억할 수 있다.
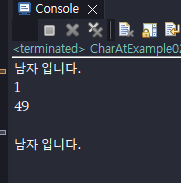
# 문자 추출 ( charAt() )
charAt() 메소드는 매개값으로 주어진 인덱스의 문자를 리턴한다.
-주민번호 앞자리에 대한 성별 구분
-특정 인덱스값을 통해 무엇을 출력할 때 사용한다
String str = "자바 프로그래밍";
char charValue = str.charAt(1);
System.out.println(charValue); // result = 바
for(int i = 0; i < str.length(); i += 1) {
char result = str.charAt(i);
System.out.print(result); // result = 자바 프로그래밍
}
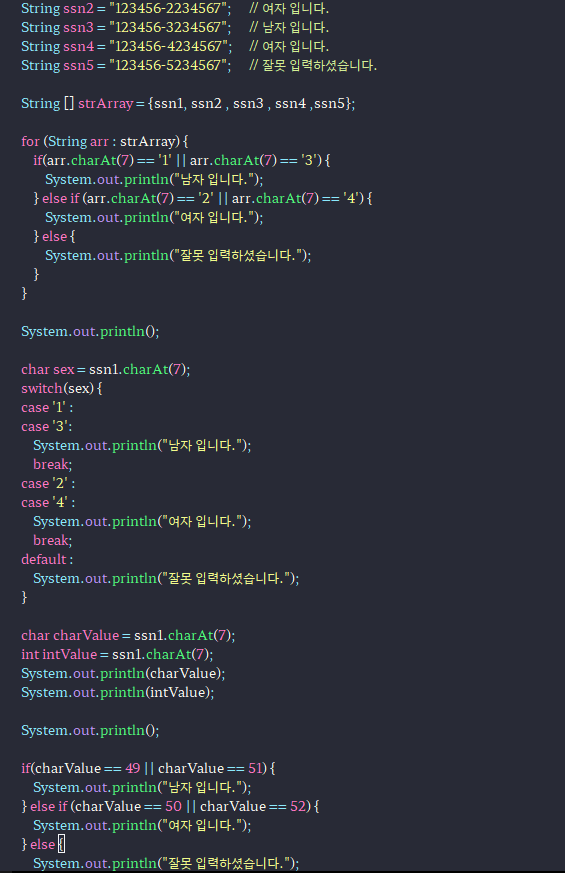
-주민등록번호 뒷자리 첫째자리를 확인해서 성별을 출력하는 예시
String ssn1 = "123456-1234567"; // 남자 입니다.
String ssn2 = "123456-2234567"; // 여자 입니다.
String ssn3 = "123456-3234567"; // 남자 입니다.
String ssn4 = "123456-4234567"; // 여자 입니다.
String ssn5 = "123456-5234567"; // 잘못 입력하셨습니다.
String [] strArray = {ssn1, ssn2 , ssn3 , ssn4 ,ssn5};
for (String arr : strArray) {
if(arr.charAt(7) == '1' || arr.charAt(7) == '3') {
System.out.println("남자 입니다.");
} else if (arr.charAt(7) == '2' || arr.charAt(7) == '4') {
System.out.println("여자 입니다.");
} else {
System.out.println("잘못 입력하셨습니다.");
}
}
char sex = ssn1.charAt(7);
switch(sex) {
case '1' :
case '3':
System.out.println("남자 입니다.");
break;
case '2' :
case '4' :
System.out.println("여자 입니다.");
break;
default :
System.out.println("잘못 입력하셨습니다.");
}
char charValue = ssn1.charAt(7);
int intValue = ssn1.charAt(7);
System.out.println(charValue);
System.out.println(intValue);
System.out.println();
if(charValue == 49 || charValue == 51) {
System.out.println("남자 입니다.");
} else if (charValue == 50 || charValue == 52) {
System.out.println("여자 입니다.");
} else {
System.out.println("잘못 입력하셨습니다.");
}
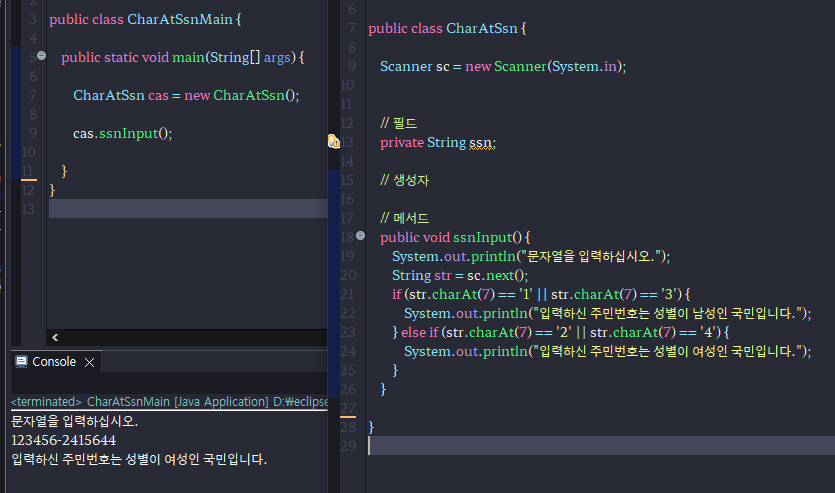
-Scanner에서 주민번호를 입력받은 뒤에 뒷 자리 첫 번째 자리를 보고 성별 구분하기
Scanner sc = new Scanner(System.in);
// 필드
private String ssn;
// 생성자
// 메서드
public void ssnInput() {
System.out.println("문자열을 입력하십시오.");
String str = sc.next();
if (str.charAt(7) == '1' || str.charAt(7) == '3') {
System.out.println("입력하신 주민번호는 성별이 남성인 국민입니다.");
} else if (str.charAt(7) == '2' || str.charAt(7) == '4') {
System.out.println("입력하신 주민번호는 성별이 여성인 국민입니다.");
}
}public static void main(String[] args) {
CharAtSsn cas = new CharAtSsn();
cas.ssnInput();
}
-Scanner에서 JOptionPane.showInputDialog를 사용하면 이런 화면으로도 입력받을 수 있다.

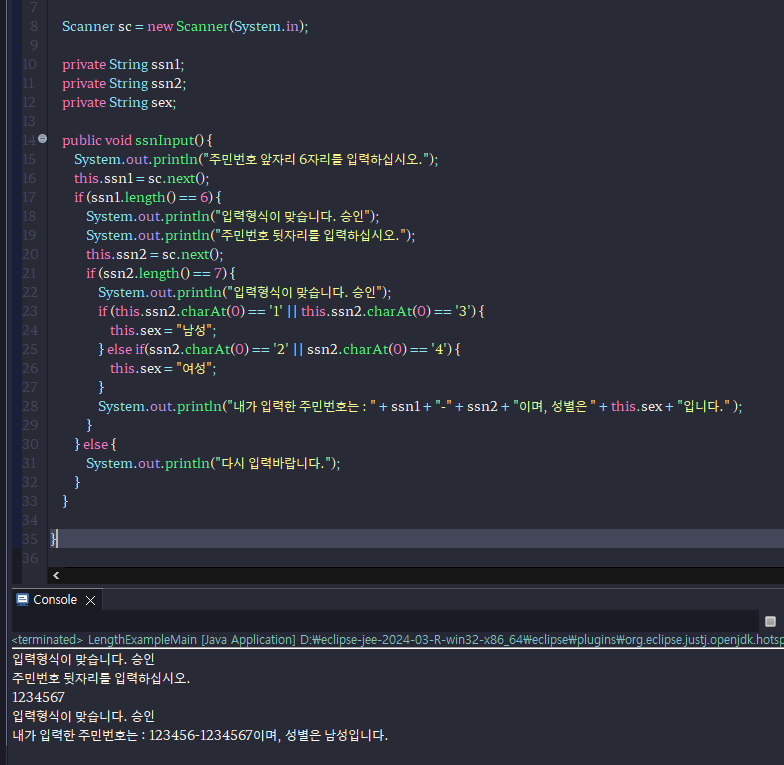
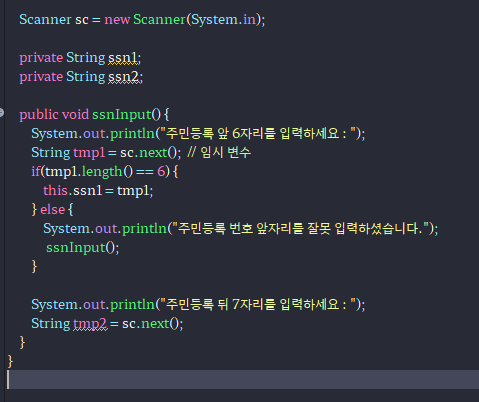
-Scanner에서 받은 주민번호의 길이와 뒷 번호 첫 번째 자리로 성별 구분하기
Scanner sc = new Scanner(System.in);
private String ssn1;
private String ssn2;
private String sex;
public void ssnInput() {
System.out.println("주민번호 앞자리 6자리를 입력하십시오.");
this.ssn1 = sc.next();
if (ssn1.length() == 6) {
System.out.println("입력형식이 맞습니다. 승인");
System.out.println("주민번호 뒷자리를 입력하십시오.");
this.ssn2 = sc.next();
if (ssn2.length() == 7) {
System.out.println("입력형식이 맞습니다. 승인");
if (this.ssn2.charAt(0) == '1' || this.ssn2.charAt(0) == '3') {
this.sex = "남성";
} else if(ssn2.charAt(0) == '2' || ssn2.charAt(0) == '4') {
this.sex = "여성";
}
System.out.println("내가 입력한 주민번호는 : " + ssn1 + "-" + ssn2 + "이며, 성별은 " + this.sex + "입니다." );
}
} else {
System.out.println("다시 입력바랍니다.");
}
}
# 문자열 찾기 ( indexOf() )
-쉽게 얘기해서 내가 쓴 문자열과 그 값이 같은 문자열을 찾아 그 문자열의 위치를 인덱스 번호로 나타내어 준다.
-코엑스라는 문자열, str.indexOf("코엑스")의 result는 0이 출력된다.
indexOf() 메소드는 매개값으로 주어진 문자열이 시작되는 인덱스를 리턴한다.
만약 주어진 문자열이 포함되어 있지 않으면 -1을 리턴한다.
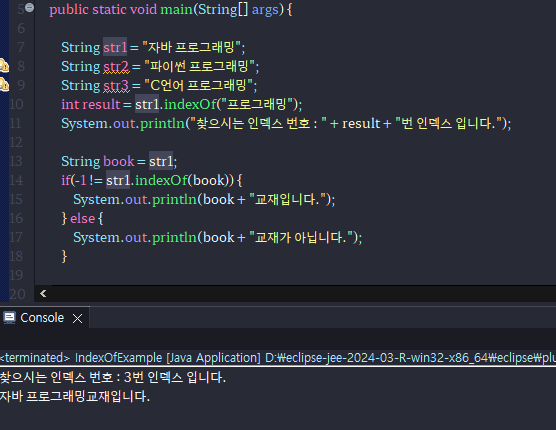
String str1 = "자바 프로그래밍";
String str2 = "파이썬 프로그래밍";
String str3 = "C언어 프로그래밍";
int result = str1.indexOf("프로그래밍");
System.out.println("찾으시는 인덱스 번호 : " + result + "번 인덱스 입니다.");
String book = str1;
if(-1 != str1.indexOf(book)) {
System.out.println(book + "교재입니다.");
} else {
System.out.println(book + "교재가 아닙니다.");
}
-주민번호 예제에서 indexOf를 활용한 것(indexOf는 해당하는 값의 인덱스 번호를 출력해주기 때문에 0번째 배열을 같다고 하여 구하고자 하는 첫째자리의 숫자를 찾는다)
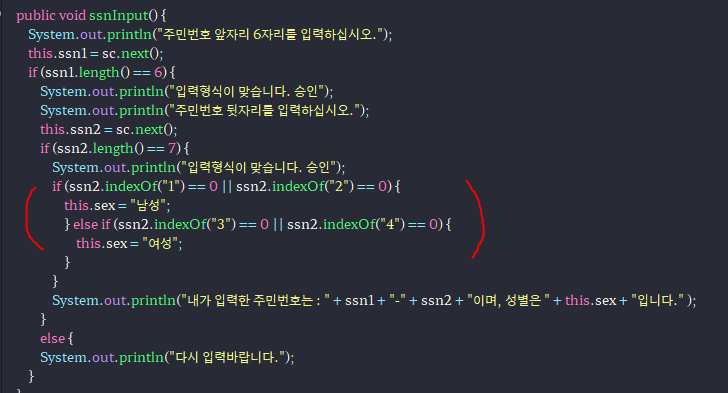
-소소한 팁인데 while문으로 값을 잘못 받으면 반복해서 받아줄 수 있겠지만, 그냥 메서드 자체를 틀렸을 경우 else문에 메서드 자체를 다시 실행시켜주면 된다.
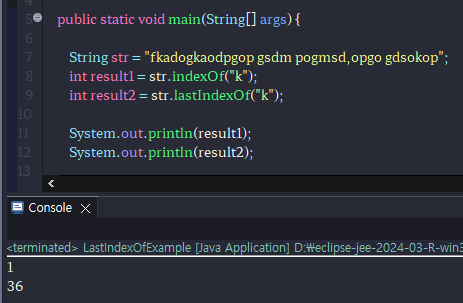
# 마지막 문자열 찾기 ( lastindexOf() )
-위의 indexOf와는 반대로 제일 마지막에 있는 문자열의 인덱스 숫자를 결과로 출력한다.
indexOf() 메소드는 매개값으로 주어진 문자열이 끝나는 인덱스를 리턴한다.
만약 주어진 문자열이 포함되어 있지 않으면 -1을 리턴한다.
-쓰임새 : 확장명 jpg, png, text 등등 확장자를 구별해내어서 받거나 받지 않을 때 사용
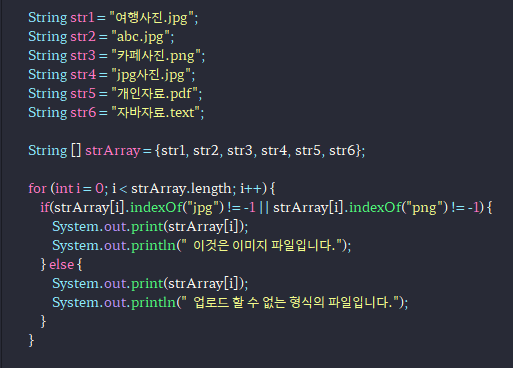
# 문자열 대치( replace() )
replace() 메소드는 첫 번째 매개값인 문자열을 찾아
두 번째 매개값인 문자열로 대치한 새로운 문자열을 생성하고 리턴한다.

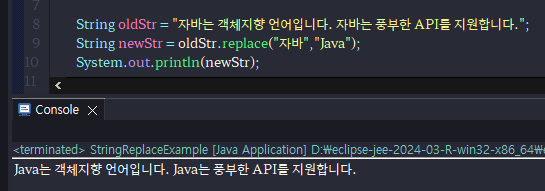
-자바라는 단어를 찾아내어서 JAVA로 변경해서 객체에 저장된다.
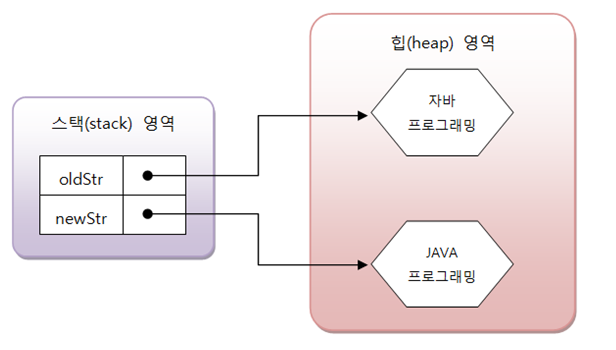
-String은 특성상 한 번 값을 저장해놓으면 문자열이 변경이 불가능하다.
-str1~str6의 값을 저장해놓고 더해놓으면 객체의 값이 변하는게 아니라 객체를 추가하여 참조해서 만들어내는 것
(아래의 그림을 참고..)
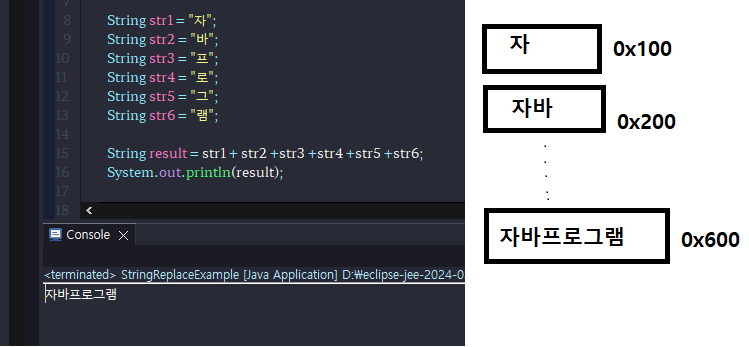
-oldStr의 값은 바꿀 수 없다. 바꾸려면은 객체를 새로만드는 수 밖에 없다.

-replace("문자열1","문자열2")를 사용하면, 문자열1의 내용이 문자열2로 바뀌어져 있는 것을 확인할 수 있다.
# 알파벳 대/소문자 변경 (toLowerCase(), toUpperCase())
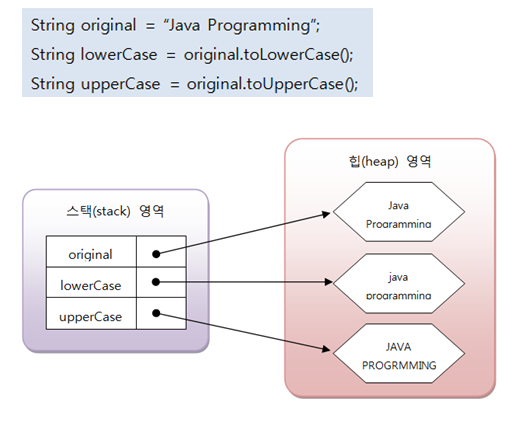
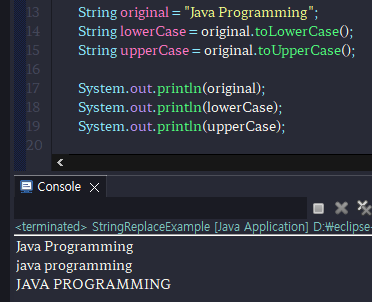
toLowerCase() 메소드는 문자열을 모두 소문자로 바꾼 새로운 문자열을 생성한 후 리턴한다.
toUpperCase() 메소드는 문자열을 모두 대문자로 바꾼 새로운 문자열을 생성한 후 리턴한다.
-당연히 한글에는 적용이 되지 않는다.
-변수명.toLowerCase() : 변수에 입력된 값 전부 소문자로 변경
-변수명.toUpperCase() : 변수에 입력된 값 전부 대문자로 변경
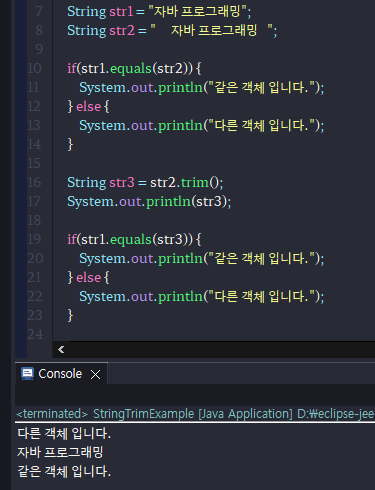
# 문자열 앞뒤 공백 잘라내기 ( trim() )
trim() 메소드는 문자열의 앞뒤 공백을 제거한 새로운 문자열을 생성하고 리턴한다.
다음 코드를 보면 newStr 변수는 새로 생성된 “자바 프로그래밍” 문자열을 참조한다.
trim() 메소드는 앞뒤의 공백만 제거할 뿐 중간의 공백은 제거하지 않는다.
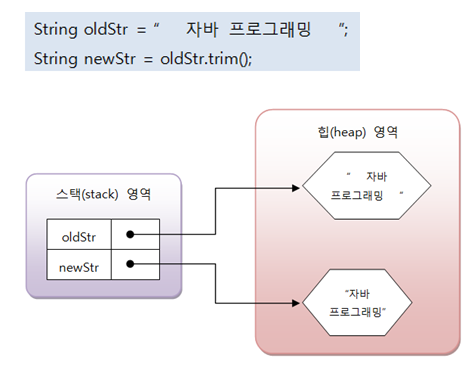
-주로 사용하는 사용처는 앞뒤 공백을 다 자르고, 이용자의 id를 확인할 때 사용한다.
-가운데에 있는 공백은 제거하지 않는다.
# 문자열 변환 ( valueOf() )
매개 변수의 타입별로 valueOf() 메소드가 다음과 같이 오버로딩되어 있다.
valueOf() 메소드는 기본 타입의 값을 문자열로 변환하는 기능을 가지고 있다.
-기본형 타입들을 문자열로 변환시켜준다.

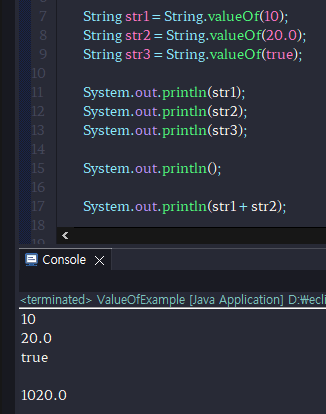
-알짜배기 문자열 타입 기본형 타입으로 변경하기
int result = Integer.parseInt(str1);
double result2 = Double.parseDouble(str2);
System.out.println(result + result2);
// char -> int로 타입 변경
(str.charAt(0)-'0')
# 문자열 잘라내기( substring() )
substring() 메소드는 주어진 인덱스에서 문자열을 추출한다.
substring () 메소드는 매개값의 수에 따라 두 가지 형태로 사용된다.
substring(int beginlndex, int endlndex)는 주어진 시작과 끝 인덱스 사이의 문자열을 추출
substring (int beginlndex)는 주어진 인덱스 이후부터 끝까지 문자열을 추출
-substring(0,6) = 인덱스 0부터 인덱스 5까지 출력
// 0번 인덱스 부터 6전까지
String ssn = "123456-1234567";
String result12 = ssn.substring(0,6);
System.out.println(result12); // 123456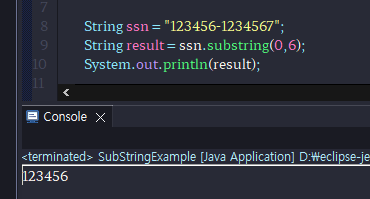
// 7번 인덱스 부터 끝까지
String result13 = ssn.substring(7);
System.out.println(result13); // 1234567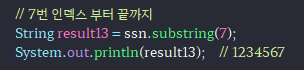
// 0번 인덱스 부터 6전까지
String ssn = "123456-1234567";
String result12 = ssn.substring(0,6);
System.out.println(result12);
// 7번 인덱스 부터 끝까지
String result13 = ssn.substring(7);
System.out.println(result13);
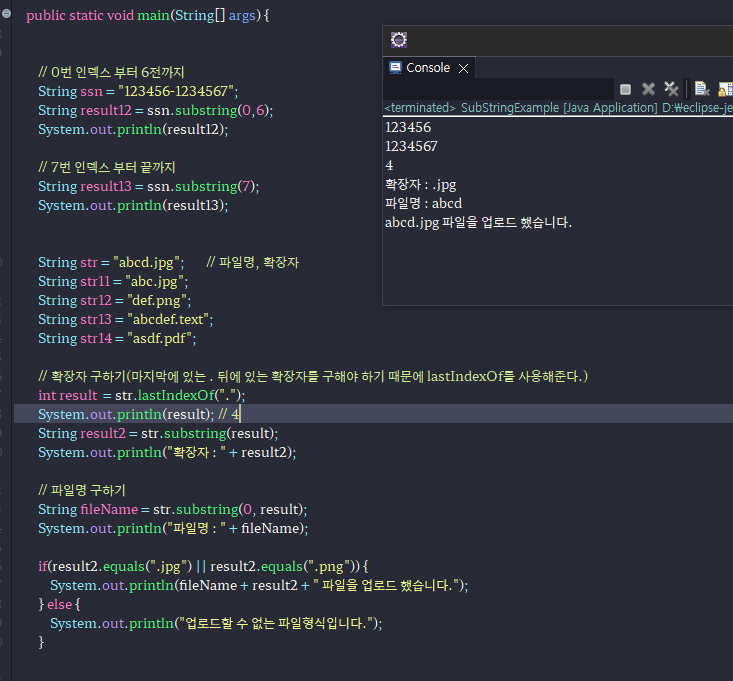
String str = "abcd.jpg"; // 파일명, 확장자
String str11 = "abc.jpg";
String str12 = "def.png";
String str13 = "abcdef.text";
String str14 = "asdf.pdf";
// 확장자 구하기(마지막에 있는 . 뒤에 있는 확장자를 구해야 하기 때문에 lastIndexOf를 사용해준다.)
int result = str.lastIndexOf(".");
System.out.println(result); // 4
String result2 = str.substring(result);
System.out.println("확장자 : " + result2);
// 파일명 구하기
String fileName = str.substring(0, result);
System.out.println("파일명 : " + fileName);
if(result2.equals(".jpg") || result2.equals(".png")) {
System.out.println(fileName + result2 + " 파일을 업로드 했습니다.");
} else {
System.out.println("업로드할 수 없는 파일형식입니다.");
}
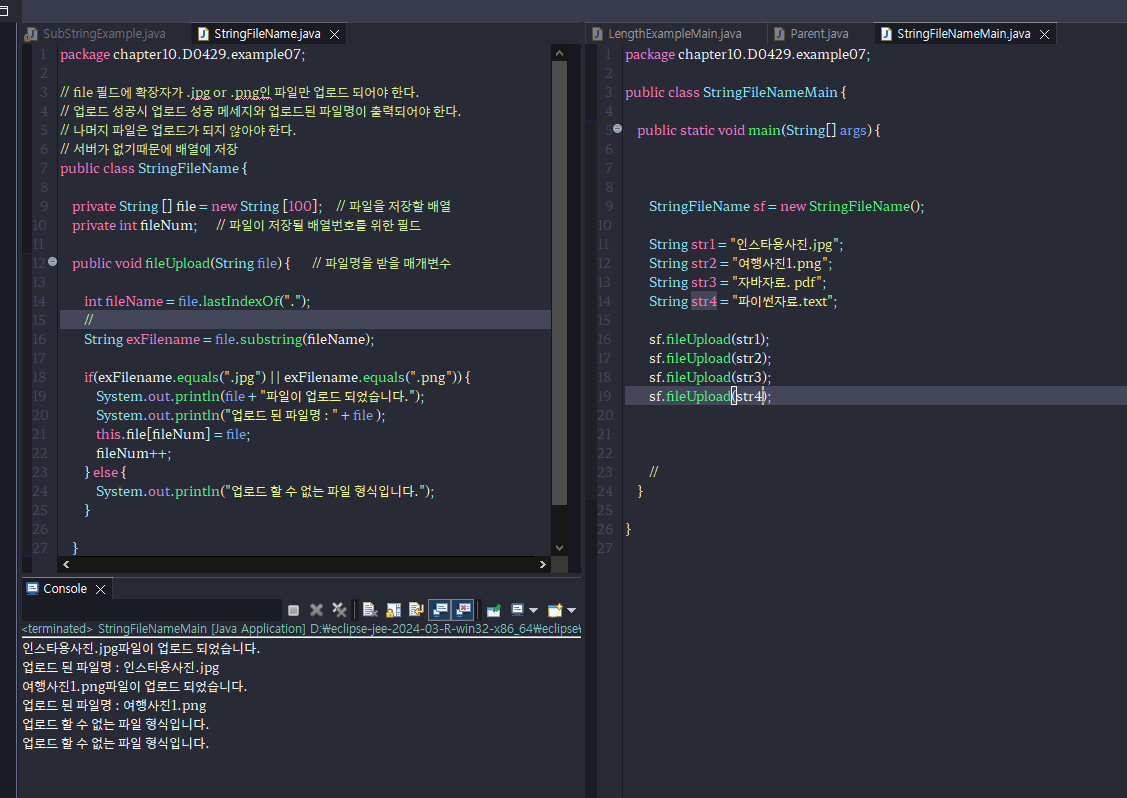
-배열의 인덱스 크기를 정해놓고, 마지막 값이 .jpg와 .png로 되어있는 확장자만 저장하는 예제
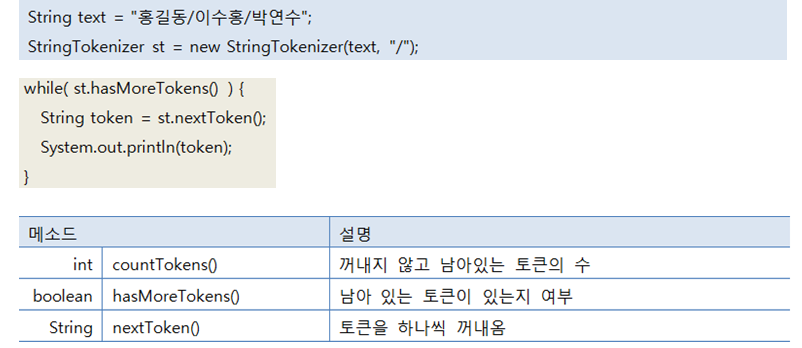
## StringTokenizer 클래스
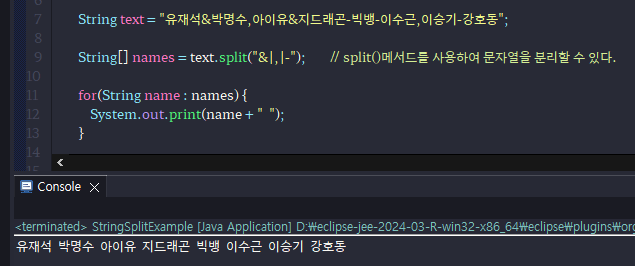
문자열이 특정 구분자(delimiter)로 연결되어 있을 경우,
구분자를 기준으로 부분 문자열을 분리하기 위해서는 String의 split() 메소드를 이용하거나,
java.util 패키지의 StringTokenizer 클래스를 이용할 수 있다.
split()은 정규 표현식으로 구분하고, StringTokenizer는 문자로 구분한다는 차이점이 있다
-String split() 메서드 사용(구분자가 여러개일 경우에도 사용이 가능하다)

- StringTokenizer 클래스 사용(구분자가 한가지일 경우에만 사용이 가능하다)
-hasMoreTokens() 토큰이 남아있는지 여부를 통해 true와 false를 나타낸다. (Exception이 발생되지 않기 위해서)
-nextToken() 토큰 즉, 아래의 홍길동 이수홍 박연수를 하나씩 꺼내온다.
-countTokens() 토큰의 갯수를 세주는데 아래의 예시에는 3개이다.
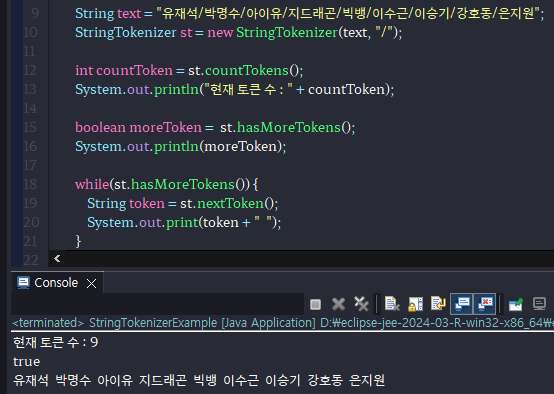
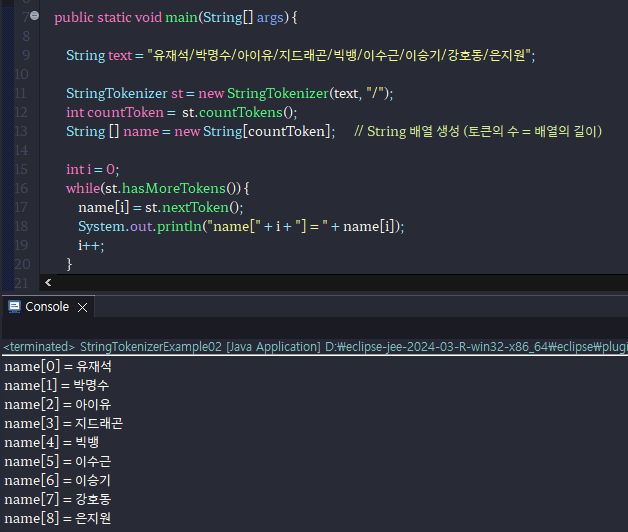
-String 배열을 생성해서, 각각의 배열에 입력된 token을 넣어주고 출력하는 예시
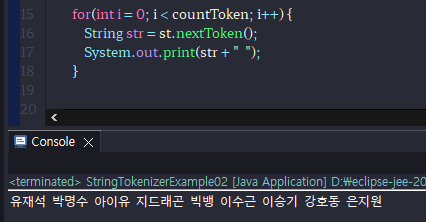
-while문이 아닌 for문으로 출력할 때
(countToken에 st.countTokens를 넣으면 st.countTokens의 갯수는 token을 하나씩 빼올 때마다 줄기 때문에, 총 5개밖에 출력이 되지 않는다.)
## StringBuffer, StringBuilder 클래스
- 잘 쓰이지 않지만, 책 한권의 분량을 내가 수정하고 저장할 때 수정하고 저장된 객체를 또 일일이 추가로 생성해서 저장을 하게 되는데, 그럴 때에는 데이터가 상당히 무거워지기 때문에, 그런 문자열의 크기가 많은 상황에서 사용한다.
문자열을 저장하는 String은 내부의 문자열을 수정할 수 없다.
예를 들어 String의 replace() 메소드는 내부의 문자를 대치하는 것이 아니라, 대치된 새로운 문자열을 리턴한다.
String 객체를 + 연산할 경우에도 마찬가지다.
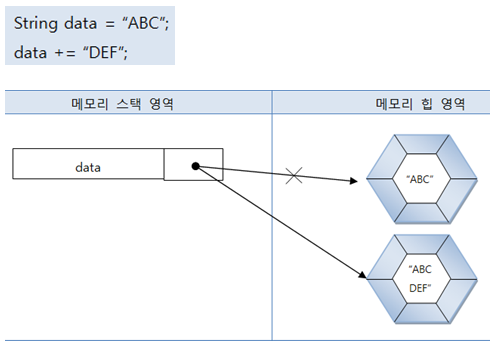
String data = "ABC";
data += "DEF";
“ABC"에 “DEF"가 추가되었기 때문에 한 개의 String 객체가 사용되었다고 생각할 수 있지만,
String 객체는 내부 데이터를 수정할 수 없으므로
"ABC"에 "DEF"가 추가된 “'ABCDEF"라는 새로운 String 객체가 생성된다.
그리고 data 변수는 새로 생성된 String 객체를 참조하게 된다.
문자열을 결합하는 + 연산자를 많이 사용하면 할수록 그만큼 String 객체의 수가 늘어나기 때문에,
프로그램 성능을 느리게 하는 요인이 된다.
문자열을 변경하는 작업이 많을 경우에는 String 클래스를 사용하는 것보다는
java.lang 패키지의 StringBuffer 또는 StringBuilder 클래스를 사용하는 것이 좋다.
이 두 클래스는 내부 버퍼 (buffer: 데이터를 임시로 저장히는 메모리)에 문자열을 저장해 두고,
그 안에서 추가, 수정, 삭제 작업을 할수 있도록 설계되어 있다.
String처럼 새로운 객체를 만들지 않고도 문자열을 조작할 수 있는 것이다.
StringBuffer와 StringBu ilder의 사용 방법은 동일한데 차이점은
StringBuffer는 멀티 스레드 환경에서 사용할 수 있도록 동기화가 적용되어 있어 스레드에 안전하지만,
StringBuilder는 단일 스레드 환경에서만 사용하도록 설계되어 있다.
-객체가 여러개 생성 되면은 데이터가 무거워지기 때문에, StringBuffer나 StringBuilder로 객체를 생성하지 않고, 문자열을 변경해줄 수 있다.
-두 개의 차이는 멀티스레드냐 단일스레드냐로 나뉜다.

-추가적으로 *를 더하는 반복문을 통해서 만들면 객체가 무수히 만들어져, 반복문이 끝나기까지 만들어지는 시간이 길어진다.

'java(2)↗' 카테고리의 다른 글
| java 중첩 클래스 (0) | 2024.05.02 |
|---|---|
| java Arrays 클래스, Boxing 박싱, Date, Format (0) | 2024.05.01 |
| java 자바 API 다양한 클래스들 (0) | 2024.04.26 |
| java 예외 (0) | 2024.04.25 |
| java 인터페이스 (0) | 2024.04.24 |